What RAG Solves
Retrieval-Augmented Generation (RAG) is an LLM pattern that answers questions by retrieving relevant facts from a knowledge base (docs, databases, wikis, APIs) right before the model writes its reply. Instead of relying only on parameters (which go stale), the model gets a fresh, targeted context window snippets, quotes, or summaries then generates an answer that cites those sources. The result is more grounded, up-to-date, and auditable responses, often with lower cost because you can pair strong retrieval with a smaller model.
LLMs are powerful but:
(a) Forget specifics,
(b) Hallucinate,
(c) Go stale.
RAG externalizes knowledge so the model “looks up” facts on demand, enabling freshness, traceability, and policy control.
End-to-End Architecture
Ingestion & Pre-processing
Connect to file stores, wikis, ticketing systems, PDFs, databases, and APIs. Clean the corpus with deduplication, boilerplate removal, OCR where needed, and language detection. Split content into chunks typically fixed sizes of 500–1,000 tokens with overlaps—and, when helpful, use hierarchical splitting (section → paragraph → sentence) so retrieval can operate at multiple granularities. Apply redaction and classification to remove or label PII and secrets before anything is indexed.Indexing
Build a sparse index (e.g., BM25) for lexical matches and a dense index with embeddings for semantic matches, using ANN structures such as HNSW or IVF-PQ for speed at scale. A hybrid index merges signals from both. Optionally, add late-interaction models (e.g., ColBERT-style multi-vector indexing) to capture precise term-level matching without losing semantic recall.Retrieval
Fetch top-K results from one or more indices while enforcing filters such as ACLs, metadata constraints, and time windows. For higher precision at the top of the list, apply cross-encoder re-ranking to refine the initial candidate set and improve precision@K.Post-retrieval Processing
Compress context by extracting key sentences, performing map-reduce summaries, or selecting quotable spans. Remove near-duplicates and promote result diversity so the final context window covers distinct, corroborating sources.Generation
Use prompt templates that enforce grounded answers with citations and the rule to “only use provided context.” Produce outputs in the required structure—JSON, bullet points, or prose—and apply guardrails appropriate to the domain.Observability & Governance
Log queries, retrieved document IDs, answers, citations, user identifiers, and timestamps. Track metrics such as retrieval recall, groundedness, latency, cost, and policy compliance. Maintain rollbacks and versioned indices, and record data lineage to support audits and reliable incident response.
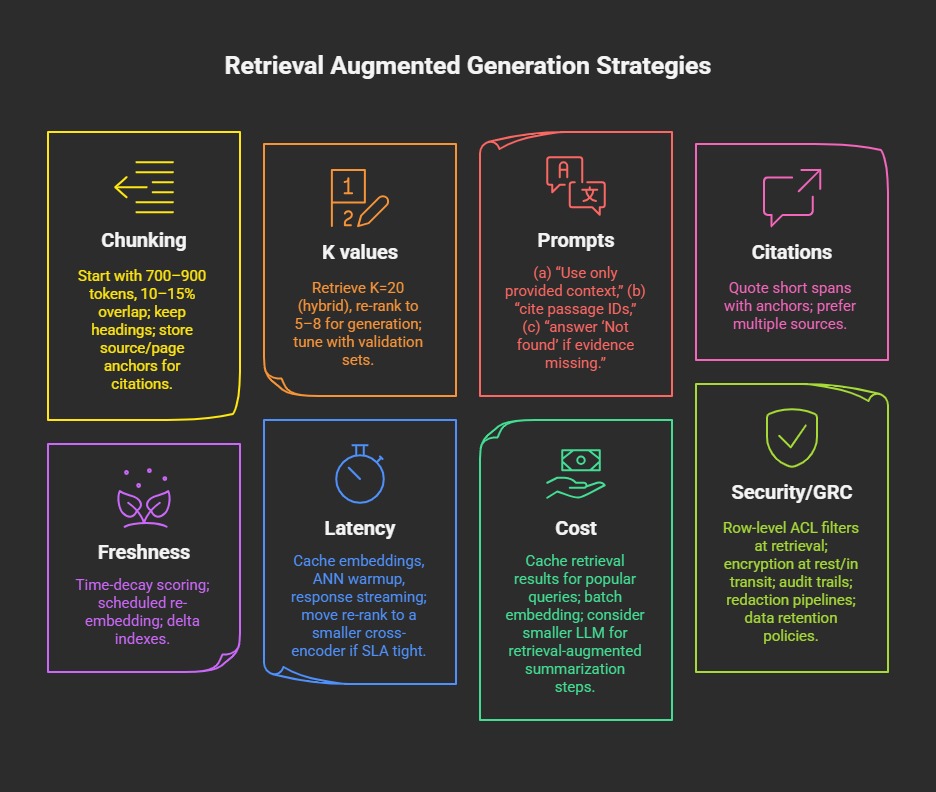
Design Choices & Practical Guidance
Chunking: start 700–900 tokens, 10–15% overlap; keep headings; store source/page anchors for citations.
K values: retrieve K=20 (hybrid), re-rank to 5–8 for generation; tune with validation sets.
Prompts: (a) “Use only provided context,” (b) “cite passage IDs,” (c) “answer ‘Not found’ if evidence missing.”
Citations: quote short spans with anchors; prefer multiple sources.
Freshness: time-decay scoring; scheduled re-embedding; delta indexes.
Latency: cache embeddings, ANN warmup, response streaming; move re-rank to a smaller cross-encoder if SLA tight.
Cost: cache retrieval results for popular queries; batch embedding; consider smaller LLM for retrieval-augmented summarization steps.
Security/GRC: row-level ACL filters at retrieval; encryption at rest/in transit; audit trails; redaction pipelines; data retention policies.
Risks & Mitigations
Hallucinations: enforce “answer only from context,” require citations, penalize uncited claims, increase K/re-rank.
Staleness: incremental indexing, time-aware scoring, source-of-truth connectors.
Leakage/Access: row-level security; redact at ingest; test with synthetic PII.
Cost/Latency creep: cache & reuse retrievals; compress context; right-size models; cap K dynamically.
Evaluation drift: rotate fresh test sets; add human spot checks.


